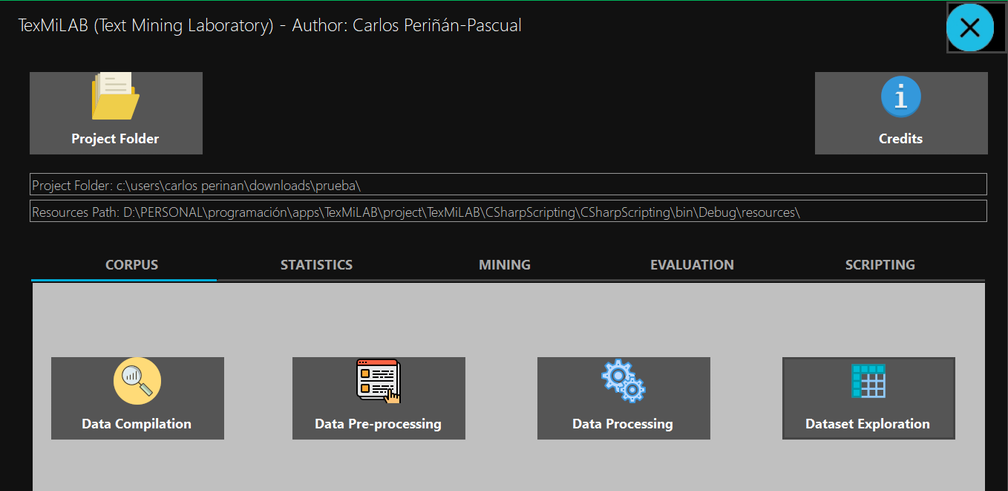
TexMiLAB is structured into five modules (i.e. Corpus, Statistics, Mining, Evaluation, and Scripting). On the one hand, the first four modules make up the complete development process of a text mining experiment. The corpus is the initial resource in this process; consequently, tools are required for the collection, management, and analysis of texts, as well as for building a semantic representation model based on co-occurrence patterns identified in the texts (Corpus). Subsequently, a statistical exploration of the dataset may be carried out in order to understand it properly (Statistics) and thus select the most suitable machine learning techniques for performing a text mining task (Mining). Finally, the quality of the model is evaluated with respect to the new knowledge that has been generated (Evaluation). On the other hand, and as an alternative, the Scripting module allows users with C# programming knowledge to implement the same experiment through code.
It enables information retrieval via RESTful APIs, access to information from RSS feeds, extraction of content from XML files, and web scraping of both static and dynamic HTML documents.
Corpus
Data
Pre-processing
It enables the conversion of PDF files to TXT, the transformation of data into other formats (e.g. CSV, JSON, and XML), and basic text modification operations (e.g. merging, splitting, and replacing). In addition, it supports many other tasks related to fields such as text analytics (e.g. keyword and named entity recognition, as well as concordance and collocation extraction) and natural language processing (e.g. language identification, word lemmatisation, and part-of-speech tagging).
It enables the creation of a document–ngram matrix for a corpus, as well as the application of techniques for reducing its dimensionality (e.g. supervised feature-selection methods and unsupervised feature-transformation methods).
Corpus
Dataset
Exploration
It enables the conversion of CSV files into tables within a SQLite database, allowing their contents to be managed through SQL statements.
Coming soon.
Mining
Text Classification
It enables text classification on a test corpus using trained machine learning models, including traditional supervised algorithms (e.g. decision trees, k-nearest neighbours, naïve Bayes, random forests, and support vector machines) and neural networks (e.g. convolutional networks).
It enables data clustering through methods such as K-means, Gaussian mixture model, agglomerative hierarchical clustering, and HDBSCAN, as well as topic modelling through methods such as probabilistic latent semantic analysis and latent Dirichlet allocation.
It enables the application of various operations to a word-embedding matrix, such as comparing, clustering, and visualising elements through their vectors; transforming the matrix (e.g. reducing the number of elements or dimensions); and computing vector compositionality.
It enables the use of transformer-based artificial intelligence models and large language models for tasks such as sentiment and emotion analysis, as well as text generation, among others.
Evaluation
Task
Evaluation
It enables the evaluation of results generated by a text classification model using various measures based on the values of a confusion matrix (e.g. accuracy, precision, recall, and F1 score, among many others). It also assists in the preparation of training and test datasets for k-fold cross-validation.
Evaluation
Data Visualisation
It enables the generation of line charts, pie charts, network graphs, and scatter plots from data in CSV format. Word vectors can also be projected onto a two-dimensional space.
It enables the execution of C# scripts in console mode, with access to the same functionalities as those available through the TexMiLAB graphical interface.